研究テーマ詳細 小野田 研究室
研究テーマ詳細
計算機の高速化,メモリの大容量化によって,学習アルゴリズムの計算機実験が容易になり,様々な学習アルゴリズム提案されるようになってきました.そのような状況の中,学習アルゴリズムを利用した実世界問題の解決を目標として,新たな学習アルゴリズムの開発,学習アルゴリズムの特性を活かした新たな問題解決法の開発を研究中です.また,機械学習と人間の有する経験知識とのインタラクションによる問題解決の効率化についても研究しています.具体的にはアンサンブル学習,サポートベクターマシンに基づく特徴選択,トランスダクティブ推論に基づく検索の効率化,外れ値検出による保守保全のスク管理,人工知能・機械学習応用について研究中です. また,実際に学生によって行われた研究は,過去の研究テーマをご覧下さい.
アンサンブル学習
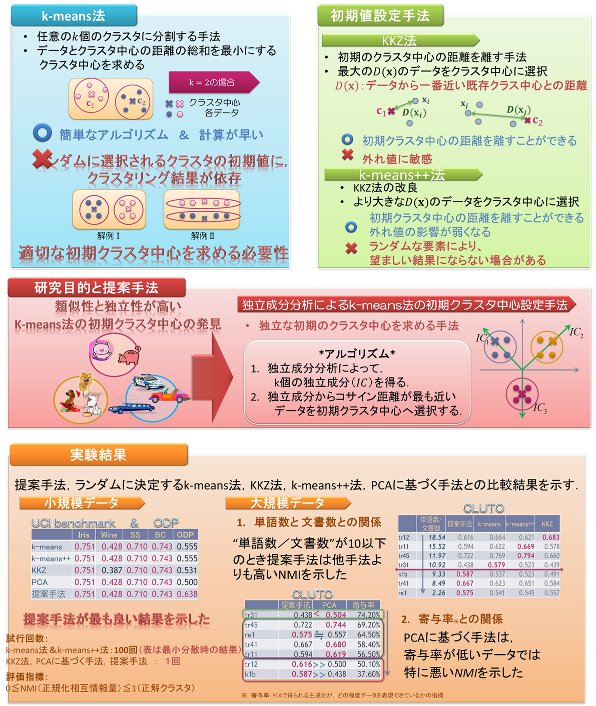
本研究室では,複数の弱学習仮説(弱識別器)の推定結果を統合してロバストな推定結果を出力するアンサンブル学習(下図参照)のアルゴリズムの改良およびその数理的な特徴の分析の研究開発に取り組んでいます.
アンサンブル学習は,基本的に弱学習仮説h1,...,htをいかに獲得し,弱学習仮説の推定結果への重み付けα1,...,αtをいかに決定して,それら弱学習仮説と推定結果への重み付けを利用していかに推定結果を統合させるかという問題である.このアンサンブル学習を実現する代表的なアルゴリズムとして,Bagging(Bootstrap aggregating)やAdaBoost(Adaptive Boosting)がある.
我々は,実験的にその汎化能力の高さが様々な文献で示されているAdaBoostに注目し,その数理的な特徴を分析するとともに,その汎化能力を更に向上するようなアルゴリズムの研究および学習を高速化するアルゴリズムの研究に取り組んでいます.
サポートベクターマシンに基づくDB構築・管理
パターン認識方法の一つであるサポートベクターマシンは,分類問題に対して非常に高い汎化性能を示し,様々な現実問題に適用され始めています.しかし,サポートベクターマシンの扱う分類問題は基本的に教師あり学習であるため,正例と負例の両方が学習の際に必要となります.現実の問題では,この正例と負例から構成される事例データベースの構築と管理に人的コストがかかることになります.我々はこの人的コストを削減しながら,汎化能力の高い分類結果が得られるような事例データベースの構築・管理方法の研究に取り組んでいます.
サポートベクターマシンに代表される高い汎化性能を示すパターン認識方法は,様々な機器診断などでもその活用が期待されています.しかし,サポートベクターマシンのような教師あり学習を用いる方法には,機器の異常例と正常例を多数収集し,正確な事例データベースを構築する必要があります(上図グレー部分).このデータベースの構築・管理には,滅多に起こらない異常例を収集しなければならない困難さと,収集したデータが異常例か正常例かを正確にラベル付けしなければならない困難さがあります.我々は,サポートベクターマシンの特性を利用して,この困難さを軽減する方法について研究しています.
トランスダクティブ推論に基づく検索の効率化
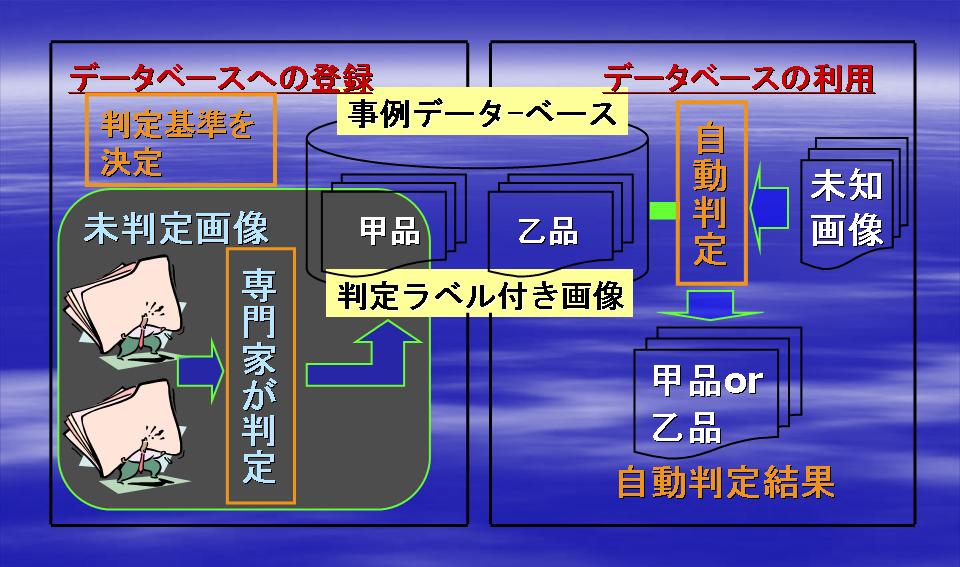
従来のキーワードを利用する文書検索ではなく,検索結果に対するユーザの評価(この文書「いる(○)」または「いらない(×)」)に基づき,ユーザの興味のある文書を効率的に見つけ出す方法(対話的文書検索方法)の開発を行っています(下図参照).
特許情報についてのデータベースや研究論文についてのデータベースなどを検索する際,簡単なキーワードを入力すると大量の文献が検索結果として提示されて困ってしまい,逆にちょっと専門的なキーワードを入力すると該当する文献がなくなってしまって困るという経験をしたことがないでしょうか.このような問題を解決するため,我々は検索結果に対するユーザの評価をすぐに反映させ,ユーザの興味のある文書を効率的に見つけ出す対話的文書検索方法について研究しています.特に,ユーザが評価していない大量の文書とトランスダクティブ推論との融合により,ユーザの興味のある文書をさらに効率的に見つけ出す対話的文書検索方法を研究してます.
外れ値検出による保守保全のリスク管理
信頼性が高いステムでは非常に稀にしか異常事象が起こらず,そのシステムを現在管理している専門家でさえ異常事象を経験したことがないという場合があります.経験したことがない,滅多に起こらない異常事象ですが,信頼性が高いステムにおいてこのような異常事象を見逃すことは,リスク管理の意味で非常に大きな問題となりかねません.我々はこのような稀にしか起こらない異常事象を的確に発見する方法の研究を行っています.
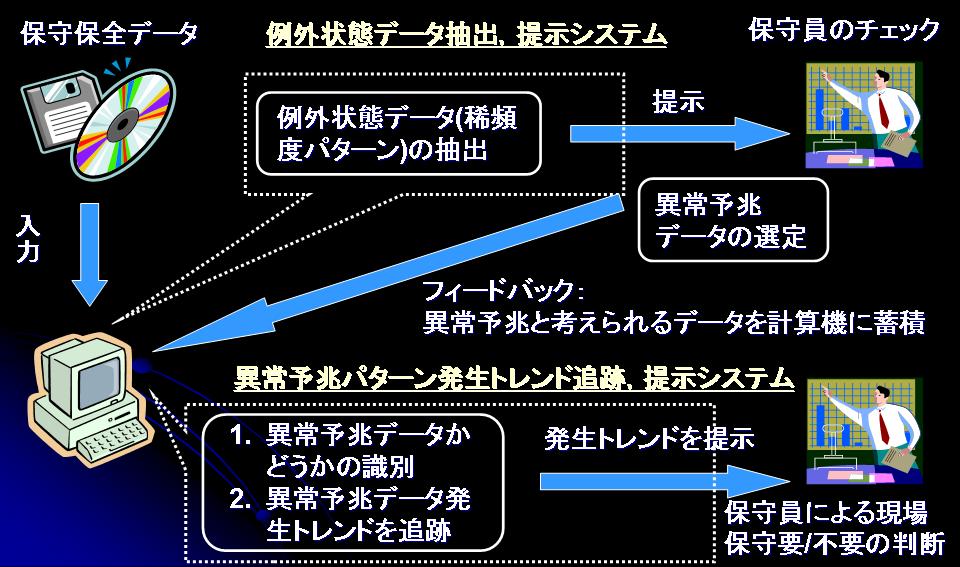
信頼性が高いステムでは非常に稀にしか異常事象が起こらないので,その異常事象を直接検出するのではなく,大量なデータからの外れ値検出手法と専門家の経験的な知識を融合した異常事象の予兆を発見する方法の研究開発に取り組んでいます.具体的には上図にあるように,与えられたデータから外れ値検出手法によって外れデータを抽出し,そのデータが異常事象に結びつきそうかどうかを専門家と吟味して,吟味して残ったデータに類似したデータの発生傾向を分析ことで異常予兆を発見する方法を研究開発しています.
腕金錆画像に基づく腕金再利用判定システム
人工知能や機械学習の技術を応用したシステムの研究開発も行っています.例えば,皆さんの身近の配電柱にある「腕金」(電線が張られているがい子を支える金属の中空角柱)は,コスト面,環境面から考えるとできるだけ廃棄せずに使用を継続したい部材です.しかし,強度的な問題があるものは危険なので使いたくありません.強度的な問題があるかどうかを「腕金」の錆の撮影画像から高精度に判別するツールを研究開発しています(下図参照).

具体的には,上図にあるように工事等で配電柱からはずされた腕金の錆のひどい部分を数箇所フード付のデジタルカメラで撮影し,再利用できるかどうかの判定を正確に行うツールを研究開発してます.フード付のデジタルカメラで撮影した画像を用いた場合,再利用判別において非常に高い正解率を実現してます.現在はフード付のデジタルカメラが利用できないような撮影環境での画像を用いた場合に高い正解率を達成できる方法を研究開発しています.
対話的文書検索(OTTER:Optimized Training TExt Retrieval)
従来のキーワードを利用する文書検索ではなく,検索結果に対するユーザの評価(この文書「いる(○)」または「いらない(×)」)に基づき,ユーザの興味のある文書を効率的に見つけ出す方法(対話的文書検索方法)の開発を行っています.「いる(○)」,「いらない(×)」のユーザ評価を2クラス分類問題と考え,この分類問題にサポートベクターマシンを適用した対話的文書検索方法(OTTER:Optimized Training TExt Retrieval)を提案し,学術文献データベースMEDLINEの検索に適用したツールを研究開発しています.従来は,ユーザ評価として「いる(○)」,「いらない(×)」の2クラスが与えられるのを前提としていましたが,提示した検索結果の文書に対するユーザ評価が「いらない(×)」のみの場合に,検索効率を上げられるように対話的文書検索方法OTTERの改良する研究開発を行っています.
小野田研究室の学生による研究テーマ






錆の進行度の順序関係を考慮した鉄塔錆画像によるメッキ劣化度判定精度の向上[長谷川2011]
送電鉄塔は,通常建て替えは行われず,表面に防錆用の溶融亜鉛メッキを塗装して使用され続けています. しかし経年とともに防錆機能は低下してしまうため, 適切な時期に再塗装を行う必要があります. 鉄塔の数は膨大であることから,再塗装スケジュールを作成するために塗装の劣化度を調査する必要があります. 客観的な劣化度調査を実現するため,鉄塔鋼材の錆画像に基づいて計算機に劣化度を自動判定させる方法が研究され,ある程度の判定精度を達成してきましたが, 更なる精度の向上が望まれています. 本研究では,錆が進行するにつれて見られる色の順序関係に着目し,色を詳細に捉えた特徴量に対して,順序関係を考慮したパターン識別手法を適用することで判定精度の向上を図りました. (下図参照)

独立成分分析による k-means法の安定な初期値設定手法の提案[坂井2011]
インターネットの普及に伴って膨大な情報が氾濫し,欲しい情報へのアクセスが難しくなっています. しかし,Yahoo!のカテゴリのように類似した情報をグループ化することで,欲しい情報へのアクセスを容易にできます. このグループ化を自動的に行う方法として,一般的にクラスタリング手法が用いられています. 特に大規模データに対して,計算コストが低いk-means法が広く利用されています. しかしk-means法には,クラスタリング結果がランダムに決められた初期値に依存してしまう問題があります. そこで本研究では,独立成分分析に基づくk-means法の安定な初期値設定手法を提案し,様々なベンチマークデータセットへの実験を行って提案手法の有用性を示しました. (下図参照)